

In this article, we are going to learn about the data structures from the Data engineering’s point of view.
There are basically three types of data structures in which data is being stored in data lakes and data warehouses. In data engineering, understanding the differences between these three types which are structured, semi-structured, and unstructured data is crucial for efficient data/information management and their analysis.
Structured Data:
Structured data is easy to search and organize. Here data is entered in a rigid structure, like a spreadsheet where there are columns and each column takes a value of a certain data type like text, data, or decimal. Structured data makes it easy to form relations and so it is organized in so-called relational databases. It’s being said that about 20% of the data is structured. SQL, which stands for Structured Query Language is used to query such data. Below is an example of structured data as it’s easy to read the table and it is well organized.
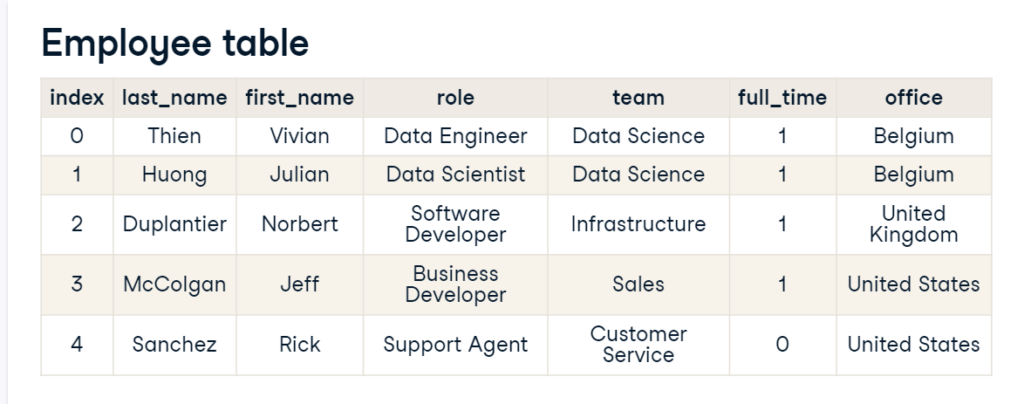
As you can see in the above example it follows a model and that’s each row expects employee data and each column has specific information about that employee (like team, roles, etc.). Here each column needs to be of a certain data type. For example, an Index column is a number and acts as a unique ID, because two employees may have the same first name, last name, or both. The full-time column holds the logical values, the values can only be true or false (1 or 0) for example, Rick Sanchez is a part-time employee and its full-time column holds 0 i.e. false. The rest of the columns are of type text.
And since it’s structured data, we can easily relate this table to other structured data. Let’s say, if there is another table holding information about offices, we can connect the office’s column of some other table with our employee table. Tables that can be connected that way form a relational database.
Semi-structured data:
Semi-structured data resembles structured data, but it allows more freedom. It’s therefore relatively easy to organize, and pretty structured, but allows more flexibility. It also has different types of data, and it can also be grouped to form relations, although this is not as straightforward as with structured data. You may have to pay for that flexibility at some point.
Semi-structured data is stored in NoSQL databases (as opposed to SQL) and usually, they’re leveraged with JSON, XML, or YAML file formats.

The above example shows a JSON file storing the favorite artists of each IEmusic (let’s say a music app) user. As you can see above the model is consistent. Each user id contains user’s last and first name, and their favorite artists. However, the number of artists may differ. As you can see the three users have different numbers of artists stored for each of them.
While relational databases don’t allow that flexibility, but semi-structured formats lets you do it.
Unstructured data:
Unstructured data is data that doesn’t follow a model and cannot be contained in rows and columns format. And this is what makes it difficult to search and organize. Unstructured data are usually texts, sounds, pictures, or videos. They’re usually stored in data lakes, although they can also appear in data warehouses or databases.
Most of the data around us is unstructured and this type of data can be extremely valuable, but because it is hard to search and organize, this value could not be extracted until recently, but with the advent of machine learning and artificial intelligence. If we take an example of our music app IEmusic then it could contains lyrics, songs, albums’ pictured and artists profile pictures and music videos as unstructured data.
Here we could use machine learning algorithms to parse song spectrums, analyze beats per minute, chord progressions, genre to help categorize songs. Or, we could have also artists give additional information when they upload their songs. Having them add the genre and some tags, would make it semi-structured data, and would make searching and organizing easier.
Conclusion:
In general we can say that, structured data is ideally used for efficient transactions and structured analysis, semi-structured data is used for more complex & adaptable scenarios while unstructured data contains comprehensive and nuanced information in the Data lakes or data warehouses.
Read further topics: Let’s understand SQL from data engineering’s point of view
3 thoughts on “Structured, semi-structured, and unstructured data in Data engineering”
Comments are closed.