
Introduction:
If you are into the learning phase of data engineering, then you might have heard about the term “data pipeline” and in this article we are going to deep dive into the same topic so let’s get started into it.
You may have heard about a quote that goes like “Data is the new oil” which was said by Clive Humby who’s a great mathematician and a data scientist entrepreneur. More or less data pipeline follows the same idea as of the extraction of the oil.
As we know that we extract the crude oil from an oil field then we move the crude oil to the distillation unit where we separate the oil into several different products.
Where some products are being sent directly to the final users. For example: some pipes go straight to airports to deliver kerosene or the other products like gasoline are sent directly to the gas storage facilities and stored in big tanks before being distributed to gas stations. Other products like Naphtha goes through some chemical transformations to create synthetic polymers for the production of the products like CDs.
Understanding data pipelines:
Similarly, in order to manage data for any for any company or organization, a similar procedure as oil processing is being followed.
Companies ingest data from different sources which needs to be processed and stored in a various way and in order to handle those data, we need data pipelines that can efficiently automate the flow from one station to the next so that the data scientist can use up-to-date, accurate, and relevant data. And all these tasks require a very good data engineering concept.
Let’s say if we’re building a music application let’s call it ‘IEmusic’. And we’ll be requiring extracting data from different sources. For example, the users’ actions or the listening history on any mobile device like from the mobile ‘IEmusic’ App, desktop ‘IEmusic’ App and ‘IEmusic’ official website itself. Please note that any company like ‘IEmusic’ can also have internal website like their HR management system for payroll and benefits.
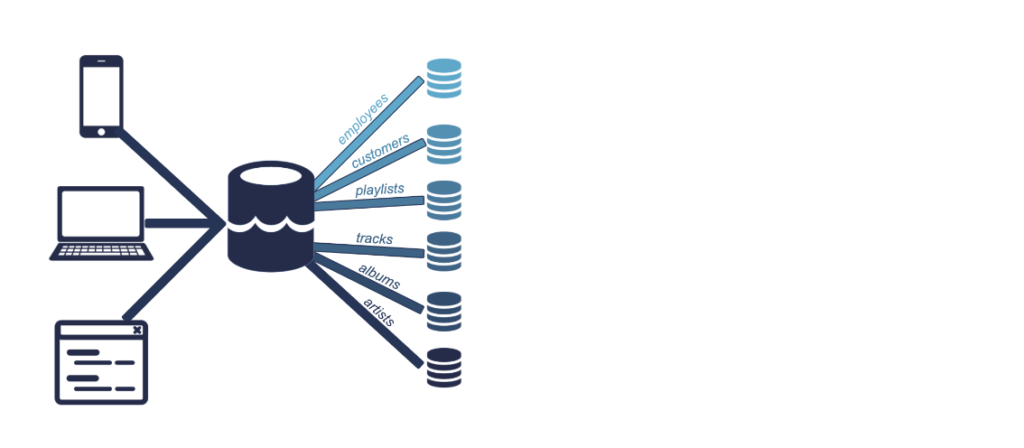
Here the data is ingested into the ‘IEmusic’ System, moving from their respective sources to our data lake. Here, mobile app, desktop app and our website is our first three pipelines. We then organize our data by moving them into databases.
They could be artist data, like their names, number of followers, and associated works.
Or it can have albums data like albums’ label, year of release
Or the data of the music tracks, like their name, length, featured artists, and number of plays etc.
playlist data, like name, songs it contains, and date of creation etc.
Customers data like username, account opening date, subscription tier etc.
Or employee data like name, salary, reporting manager, updated by human resources.
These are the six new pipelines from where let’s say an album data can be extracted and stored directly. For example, all of the album cover pictures will have the same format, so we can store them directly having to crop them.
Here one more pipeline can be added as employees could be split in different tables by department, for example sales, engineering, support, etc. These tables can even further split by office, for example: US office, the UK ofc, Belgium etc. If data scientist had to analyze employee data (let’s say to investigate employee turnover) then this is the data that can be used for employees.
Let’s add three more pipelines for tracks, as tracks would need to be processed, first to check if the track is readable, then to check if the corresponding artist is in the database, to make sure the file is in the correct size and format etc. Here we will add one more pipeline that would require data processing.
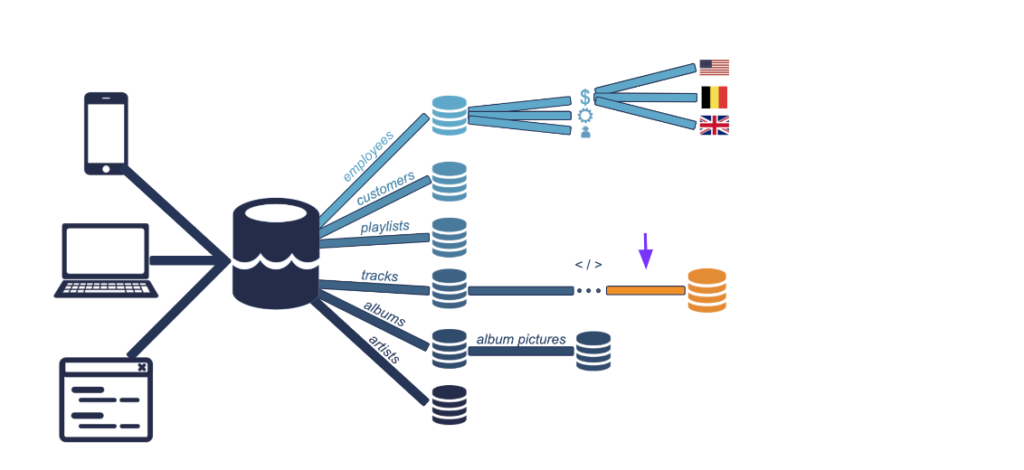
These data can then be stored in a new, clean tracks database. This would be the one of the databases that data scientists could use to build a recommendation engine by analyzing songs for similarity.
I know I discussed about a lot of pipelines in this article but in a real-life project these pipelines can be extended to large numbers as well. Because data pipelines ensure the data flows efficiency through the organization. As they automate extracting, transforming, combining, validating, & loading data to reduce human inventions and errors, also the time it takes to flow through the organization.
ETL and data pipelines:
One term you’ll hear a lot in data engineering is ETL that stands for Extraction, transformation & Loading. It’s a very popular framework for designing data pipelines. It basically breaks up the flow of the data into three sequential steps:
- Extract data
- Transform extracted data
- Loading transformed data to another database.
Data pipelines:
The key here is that data is processed before it’s stored. In general, data pipelines move data from one system to another. They may follow ETL but not all the time. For instance, data may not be transformed and routed directly to application like visualization tools or salesforce.