

In the world of Data engineering or Data analysts/scientists you may have heard of SQL language many a times by now. So, let’s understand SQL from data engineering’s point of view which is so fundamental language in the world of data science.
Introduction to SQL:
SQL stands for structured query language. In simple terms SQL is to the databases what English is to pop music. It’s the most preferred language to query RDBMS (that’s Relational Database Management System). Basically, this system gathers several tables like Employee table of any organization, and where all tables are related to each other.
SQL has two main advantages, first that it allows you to access many records at once, and group, filter or aggregate them. Now you may be thinking that most programming languages can also do that, but SQL was the first one, which is why it’s been very influential. It’s a little bit like the Beatles and pop music. It’s also very close to English language, which makes it easy to write and understand.
As you may already know that engineers use SQL to create and maintain databases while data scientists use SQL to query databases.
We’re not going to learn SQL in this article as there’re many useful resources already available on the Internet to learn SQL language. However, looking at some examples will help your understanding. Let’s look at a data engineering example first, creating a table.
Let’s create a virtual application ‘IEmusic’ and create its employee table.
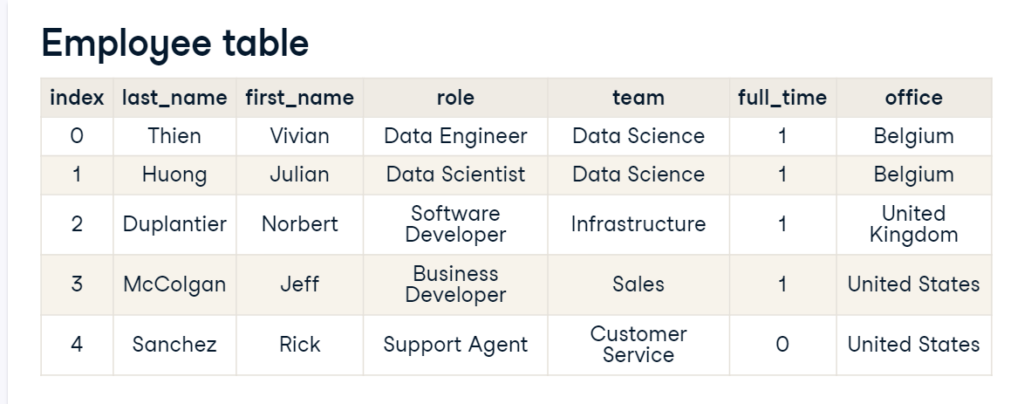
In the above example, the first column holds non-decimal numbers, the penultimate ones store logical values, and the others hold text values only.
Table creation:
We can create such a table using SQL. To do that, we type the command CREATE TABLE, and declare the name of the table “employees”. Then we proceed to create the first column, employee id, and specify the type of data expected, like integers – which mean this column will only accept whole numbers, without decimal. We then create the second column, first_name, and specify it should be text (VARCHAR stands for “variable characters”) where the values (255) entered here means that the value entered can’t be more than 255 characters long. And we do the same for the last_name, role and team.
We declare full_time as a Boolean, which is the type for logical values. This column can only hold zero for false or one for true.

Querying data from tables:
Data engineers then run other statements to update the table and write records into it where data scientists will then use SQL to Query the table. For example, a data scientist let’s called Julian, wants to get first and last name of all employees while role title contains the keyword data, he can select the first_name and last_name
from employees table where the role like table contains data. Where the percentage sign on each side of “Data” mean “Data” can appear anywhere in the role title. Attached example below:

Relational Database:
So far, we’ve looked at tables individually. But the databases are made of many tables. The database schema governs how tables are related to each other. Let’s take an example of our music app “IEmusic”, we have a table for albums, containing columns for the album’s unique ID, the artist’s unique ID, the title of the album, etc.
We also have an artist’s table, containing columns for the artist unique ID, the artist’s name and their biography. The artist table can then be linked to the album’s table the artist ID.

We also have a songs table with columns for the song unique ID, album ID song title, etc. The songs table can be linked to the album’s table through the album ID. Also, we have a playlist table with columns for a playlist unique ID, the ID of the user that created it, the song ID, etc. We can link playlist table to the songs table through the songs ID. Also, we could have other tables for labels, genres, users, etc.
Now you know why these are called “relational databases”? As multiple tables can be related to each other.
Different Implementations of SQL:
Finally, there are several implementations of SQL. Please refer to the below list:
- SQLite
- MySQL
- PostgreSQL
- Oracle SQL
- SQL Server
Switching from one to the other is like switching from a QWERTY keyboard to AZERTY one or switching from British English to American English.
Also read: Understanding Data Engineering in a lay man’s language
2 thoughts on “Let’s understand SQL from data engineering’s point of view”
Comments are closed.